Objectif
Grâce à la base de données csv de l'INSEE, réussir à calculer la fréquence d'attribution de son prénom et en faire un graphique. Personnellement comme je me prénomme "Pierre", je me demande par exemple qu'elle est le classement de ce prénom? Comment son attribution se fait de 1900 à 2019?
Résultat recherché, un truc comme cela...
Article créé sur une idée de ma collègue de SNT, D. Rambaud, merci à elle.
La source des données
Les fichiers proposés en téléchargement recensent les naissances et non pas les personnes vivantes une année donnée. Ils sont proposés dans deux formats (DBASE et CSV). Pour utiliser ces fichiers volumineux, il est recommandé d'utiliser un gestionnaire de bases de données ou un logiciel statistique. Le fichier au niveau national peut être ouvert à partir de certains tableurs. Le fichier au niveau départemental est en revanche trop volumineux (3,5 millions de lignes) pour pouvoir être consulté avec un tableur.
- Lien vers la page de l'INSEE consacrée aux prénoms
https://www.insee.fr/fr/statistiques/2540004 - Lien vers le dossier zippé de l'INSEE (le fichier France hors Mayotte des prénoms)
https://www.insee.fr/fr/statistiques/fichier/2540004/nat2019_csv.zip
Mise en place
Les liens
Liens vers les fichiers csv non-archivés pour permettre à python d'y accéder directement.
- Fichier csv simplifié à utiliser pour les tests (2Ko)
https://www.ipa-troulet.fr/cours/attachments/article/577/nat2019_simplifie.csv - Fichier csv complet à utiliser pour votre quête personnelle (11,6 Mo)
https://www.ipa-troulet.fr/cours/attachments/article/577/nat2019.csv
Structure du csv simplifié
Remarque:
- La structure du fichier nat2019.csv est identique à celle du fichier nat2019_simplifie.csv mais il contient plus de 652 000 lignes !!!!
- Pour mieux visualiser les copies d'écran, faire un clic droit / ouvrir dans un nouvel onglet par exemple.
|
Avec le bloc note (ou votre tableur) nous pouvons voir ceci:
|
Vue avec le bloc note |
Vue avec LibreOffice |
Découvertes des données avec Pandas
Voyons ici ce que pandas peut faire avec un csv. Le csv que j'utilise est le nat2019_simpifié de la page d'avant. L'idée est de tester mes essais sur les 143 lignes avant de me lancer dans les méandres du 1/2 million de lignes du fichier source!
- Attention, vous devez avoir installé la bibliothèque pandas dans votre IDE!!!
Pour vous aider voir ici.
| Vous pouvez le télécharger puis le lire en local en utilisant ceci si le csv et le programme sont dans le même dossier: | Mais vous pouvez aussi utiliser cela pour impressionner vos parents: |
|
|
Tester puis comprendre le script suivant
Ma préférence allant à l'accès à distance, je déclare l'url dans la variable texte url puis l'utilise dans la commande pandas pd.read_csv() d'ou ce script...
Pour faciliter la lecture du résultat vous noterez les print("n°").
#ceci est un script
#ouverture du csv et creation d'un dataFrame
import pandas as pd
url="https://www.ipa-troulet.fr/cours/attachments/article/577/nat2019_simplifie.csv"
donnees = pd.read_csv(url, sep=";",encoding="utf-8")
#
print("1 donnees est un dataframe")
print(type(donnees))
print(len(donnees))
print()
print("2 types de données dans la table")
print(donnees.dtypes)
print()
print("3 index ou champs (étiquettes) de la table")
print(donnees.columns)
print()
print("4 étendue (nbre de lignes avec les étiquettes) de la table")
print(donnees.index)
print()
print("5 affichage des premières et dernières lignes")
print(donnees)
print()
print("5 affichage des premières et dernières lignes")
print(donnees.describe)
print()
print("6 affichage toutes les valeurs")
print(donnees.values)
print()
print("7 transforme le dataframe en list")
maliste=donnees.values.tolist()
print(maliste)
print()
print("8 affichage d'un élément")
print(donnees.values[0])
print(donnees.values[0][1])
print(maliste[0][2])
print()
Explication de texte du résultat
A la lecture du résultat du dessus, faire attention à :
- donnees est un dataframe de 142 lignes de données n° de 0 à 141, le len(donnees) me le confirme!
- la première ligne du csv est transformée en index et n'est pas décomptée
- je peux transformer mon dataframe en list (voir le 7)
\\ Attention ceci n'est pas un script//
>>> %Run 'python dpt2019 simplifie.py'
1 donnees est un dataframe
<class 'pandas.core.frame.DataFrame'>
142
2 types de données dans la table
sexe int64
preusuel object
annais object
nombre int64
dtype: object
3 index ou champs (étiquettes) de la table
Index(['sexe', 'preusuel', 'annais', 'nombre'], dtype='object')
4 étendue (nbre de lignes avec les étiquettes) de la table
RangeIndex(start=0, stop=142, step=1)
5 affichage des premières et dernières lignes
sexe preusuel annais nombre
0 1 INDY 2013 3
1 1 INDY 2014 6
2 1 INDY 2016 4
3 1 INDY 2017 7
4 1 INDY 2018 10
.. ... ... ... ...
137 2 JEANNE 1901 14963
138 2 JEANNE 1902 14927
139 2 JEANNE 1903 15017
140 2 JEANNE 1904 14908
141 2 JEANNE 1905 15114
[142 rows x 4 columns]
5 affichage des premières et dernières lignes
<bound method NDFrame.describe of sexe preusuel annais nombre
0 1 INDY 2013 3
1 1 INDY 2014 6
2 1 INDY 2016 4
3 1 INDY 2017 7
4 1 INDY 2018 10
.. ... ... ... ...
137 2 JEANNE 1901 14963
138 2 JEANNE 1902 14927
139 2 JEANNE 1903 15017
140 2 JEANNE 1904 14908
141 2 JEANNE 1905 15114
[142 rows x 4 columns]>
6 affichage toutes les valeurs
[[1 'INDY' '2013' 3]
[1 'INDY' '2014' 6]
[1 'INDY' '2016' 4]
[1 'INDY' '2017' 7]
[1 'INDY' '2018' 10]
[1 'INDY' '2019' 4]
[1 'INDY' 'XXXX' 11]
[1 'INEL' '1917' 3]
[1 'INEL' '1922' 3]
[1 'INEL' '1925' 3]
(J'ai suppr qq lignes mais elles y sont toutes)
[2 'JEANNA' '2004' 3]
[2 'JEANNA' '2005' 4]
[2 'JEANNA' '2006' 4]
[2 'JEANNA' '2009' 3]
[2 'JEANNA' '2010' 5]
[2 'JEANNA' '2011' 6]
[2 'JEANNA' '2012' 6]
[2 'JEANNA' '2013' 5]
[2 'JEANNA' '2014' 5]
[2 'JEANNA' '2015' 10]
[2 'JEANNA' '2016' 6]
[2 'JEANNA' '2017' 7]
[2 'JEANNA' '2018' 9]
[2 'JEANNA' '2019' 6]
[2 'JEANNA' 'XXXX' 42]
[2 'JEANNE' '1900' 13981]
[2 'JEANNE' '1901' 14963]
[2 'JEANNE' '1902' 14927]
[2 'JEANNE' '1903' 15017]
[2 'JEANNE' '1904' 14908]
[2 'JEANNE' '1905' 15114]]
7 transforme le dataframe en list
[[1, 'INDY', '2013', 3], [1, 'INDY', '2014', 6], [1, 'INDY', '2016', 4], [1, 'INDY', '2017', 7], [1, 'INDY', '2018', 10], [1, 'INDY', '2019', 4], [1, 'INDY', 'XXXX', 11], [1, 'INEL', '1917', 3], [1, 'INEL', '1922', 3], [1, 'INEL', '1925', 3], [1, 'INEL', '1926', 3], [1, 'INEL', '1930', 3], [1, 'INEL', '1932', 4], [1, 'INEL', '1934', 6], [1, 'INEL', '1937', 3], [1, 'INEL', '1938', 8], [1, 'INEL', '1939', 6], [1, 'INEL', '1940', 5], [1, 'INEL', '1941', 7], [1, 'INEL', '1942', 3], [1, 'INEL', '1943', 3], [1, 'INEL', '1944', 4], [1, 'INEL', '1945', 4], [1, 'INEL', '1947', 4], [1, 'INEL', '1948', 3], [1, 'INEL', '1950', 3], [1, 'INEL', '1951', 4], [1, 'INEL', '1952', 7], [1, 'INEL', '1953', 4], [1, 'INEL', '1954', 4], [1, 'LILAN', '2009', 3], [1, 'LILAN', 'XXXX', 19], [1, 'LILIAM', '2005', 3],
J'ai suppr aussi des données
[2, 'JEANNA', '1924', 4], [2, 'JEANNA', '1929', 3], [2, 'JEANNA', '1932', 3], [2, 'JEANNA', '1985', 9], [2, 'JEANNA', '1986', 7], [2, 'JEANNA', '1987', 3], [2, 'JEANNA', '1988', 11], [2, 'JEANNA', '1989', 5], [2, 'JEANNA', '1990', 5], [2, 'JEANNA', '1991', 3], [2, 'JEANNA', '1992', 3], [2, 'JEANNA', '1996', 3], [2, 'JEANNA', '1997', 3], [2, 'JEANNA', '1999', 3], [2, 'JEANNA', '2003', 4], [2, 'JEANNA', '2004', 3], [2, 'JEANNA', '2005', 4], [2, 'JEANNA', '2006', 4], [2, 'JEANNA', '2009', 3], [2, 'JEANNA', '2010', 5], [2, 'JEANNA', '2011', 6], [2, 'JEANNA', '2012', 6], [2, 'JEANNA', '2013', 5], [2, 'JEANNA', '2014', 5], [2, 'JEANNA', '2015', 10], [2, 'JEANNA', '2016', 6], [2, 'JEANNA', '2017', 7], [2, 'JEANNA', '2018', 9], [2, 'JEANNA', '2019', 6], [2, 'JEANNA', 'XXXX', 42], [2, 'JEANNE', '1900', 13981], [2, 'JEANNE', '1901', 14963], [2, 'JEANNE', '1902', 14927], [2, 'JEANNE', '1903', 15017], [2, 'JEANNE', '1904', 14908], [2, 'JEANNE', '1905', 15114]]
8 affichage d'un élément
sexe
[1 'INDY' '2013' 3]
INDY
2013
Bilan
Ok, je peux donc rapidement comprendre le contenu d'un fichier csv avec quelques commandes. J'ai confiance, pas vous?
Données, Pandas et quelques calculs
Pour aller plus loin, sachez que pandas est aussi redoutable en manipulation de données et en calculs. Pour preuve ce qui suit. En dessous quelques liens pour vous permettre d'approfondir si jamais vous vous lancez dans l'analyse des données structurées dans le cadre de votre projet de grand oral en terminal...
|
Lien pointant vers un site présentant les commandes de bases pour pandas |
Lien pointant vers la documentation officielle pandas.org: Vous mettez la commande qui vous intéresse et regardez les propositions |
Tester puis comprendre
#ceci est un script
import pandas as pd
url="https://www.ipa-troulet.fr/cours/attachments/article/577/nat2019_simplifie.csv"
donnees = pd.read_csv(url, sep=";",encoding="utf-8")
#
print(" Pour rappel Table de donnée")
print(donnees)
print()
#
print("1 exemple tri des données")
print(donnees.sort_values(by='nombre',ascending=False))
print(donnees.sort_values(by = ['annais', 'nombre'], ascending = [True, False]))
# affectation d'un dataframe trié à un autre dataframe
maliste_tri=donnees.sort_values(by = ['annais', 'nombre'], ascending = [True, False])
print("une valeur =",maliste_tri.values[0][3])
print()
#
print("2 exemple de filtre des données")
print(donnees.loc[donnees['preusuel']=="INDY",:])
print(donnees.loc[(donnees['preusuel']=="INDY") & (donnees['annais']>="2016"),:])
monfiltre=donnees.loc[(donnees['preusuel']=="INDY") & (donnees['annais']>="2016"),:]
calc=monfiltre.values[0][3]+monfiltre.values[1][3]
print("un calcul =",calc)
print()
#
print("3 analyse des données")
print(donnees.describe(include='all'))
print("***")
print(donnees.shape)
print(donnees.count())
print(donnees.mean())
print()
#
print("4 décompte des valeurs d'un index")
print(donnees['preusuel'].value_counts())
print(donnees['sexe'].value_counts())
print()Explication de texte du résultat
A la lecture du résultat du dessous je comprends:
- que je peux trier, extraire, et calculer
- que les données d'un dataframe s'appelle avec la méthode .values ce qui n'est pas le cas des données d'une liste
\\ceci n'est pas un script//
>>> %Run 'python dpt2019 simplifie.py'
Pour rappel Table de donnée
sexe preusuel annais nombre
0 1 INDY 2013 3
1 1 INDY 2014 6
2 1 INDY 2016 4
3 1 INDY 2017 7
4 1 INDY 2018 10
.. ... ... ... ...
137 2 JEANNE 1901 14963
138 2 JEANNE 1902 14927
139 2 JEANNE 1903 15017
140 2 JEANNE 1904 14908
141 2 JEANNE 1905 15114
[142 rows x 4 columns]
1 exemple tri des données
sexe preusuel annais nombre
141 2 JEANNE 1905 15114
139 2 JEANNE 1903 15017
137 2 JEANNE 1901 14963
138 2 JEANNE 1902 14927
140 2 JEANNE 1904 14908
.. ... ... ... ...
32 1 LILIAM 2005 3
107 2 JEANNA 1929 3
108 2 JEANNA 1932 3
30 1 LILAN 2009 3
0 1 INDY 2013 3
[142 rows x 4 columns]
sexe preusuel annais nombre
136 2 JEANNE 1900 13981
137 2 JEANNE 1901 14963
138 2 JEANNE 1902 14927
139 2 JEANNE 1903 15017
140 2 JEANNE 1904 14908
.. ... ... ... ...
105 2 JEANISE XXXX 18
96 2 JEANINNE XXXX 16
85 2 ELIORA XXXX 15
6 1 INDY XXXX 11
102 2 JEANIQUE XXXX 11
[142 rows x 4 columns]
une valeur = 13981
2 exemple de filtre des données
sexe preusuel annais nombre
0 1 INDY 2013 3
1 1 INDY 2014 6
2 1 INDY 2016 4
3 1 INDY 2017 7
4 1 INDY 2018 10
5 1 INDY 2019 4
6 1 INDY XXXX 11
sexe preusuel annais nombre
2 1 INDY 2016 4
3 1 INDY 2017 7
4 1 INDY 2018 10
5 1 INDY 2019 4
6 1 INDY XXXX 11
un calcul = 11
3 analyse des données
sexe preusuel annais nombre
count 142.000000 142 142 142.000000
unique NaN 13 80 NaN
top NaN JEANNA XXXX NaN
freq NaN 30 9 NaN
mean 1.626761 NaN NaN 633.640845
std 0.485377 NaN NaN 2990.967917
min 1.000000 NaN NaN 3.000000
25% 1.000000 NaN NaN 3.000000
50% 2.000000 NaN NaN 5.000000
75% 2.000000 NaN NaN 10.000000
max 2.000000 NaN NaN 15114.000000
***
(142, 4)
sexe 142
preusuel 142
annais 142
nombre 142
dtype: int64
sexe 1.626761
nombre 633.640845
dtype: float64
4 décompte des valeurs d'un index
JEANNA 30
INEL 23
DANNY 15
LILIAN 15
JEANINNE 11
DANUTA 10
ELIORA 8
INDY 7
LILIAM 6
JEANIQUE 6
JEANNE 6
JEANISE 3
LILAN 2
Name: preusuel, dtype: int64
2 89
1 53
Name: sexe, dtype: int64
Données, Pandas et quelques graphiques
Première approche des graphiques, nous aurons donc besoin en plus de la bibliothèque matplotlib.
Pour aller encore plus loin, voici de quoi passer l'horizon ;)
|
Lien pointant vers un site présentant les commandes de bases pour matplotlib |
Lien pointant vers la documentation officielle pandas.org: |
Tester puis comprendre
#ceci est un script
import pandas as pd
url="https://www.ipa-troulet.fr/cours/attachments/article/577/nat2019_simplifie.csv"
donnees = pd.read_csv(url, sep=";",encoding="utf-8")
#
print("les données sources")
print(donnees)
#
print(" Mon choix = INDY")
df=donnees.loc[donnees['preusuel']=="INDY",:]
print(df)
#
print("Je suppr les XXXX de annais")
df.drop( df[df['annais']=="XXXX"].index, inplace=True)
print(df)
print("Je suppr les colonnes sexe et preusuel")
del df['sexe'],df['preusuel']
print(df)
#
import matplotlib.pyplot as plt
df = df.set_index('annais')
df.plot(kind='bar', title='effectif du prénom')
plt.show()
Explication de texte du script
Les dernières lignes représentent graphiquement toutes les données numériques du dataframe, c'est pour cela que je supprime toutes les données pour ne garder que deux index: annais et nombre.
Evidement les prints ne sont là que pour comprendre...
Ma quête - évolution de mon prénom depuis 1900
Notre quête étant de réaliser un graphique de son prénom de 1900 à 2019, je vous signale que vous êtes à quelques clics de la solution. Je rappelle que la base complète se trouve à cette url
https://ipa-troulet.fr/cours/attachments/article/577/nat2019.csv
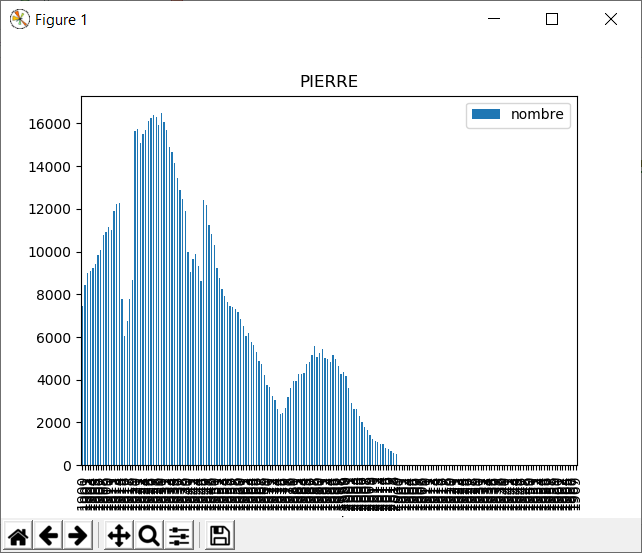
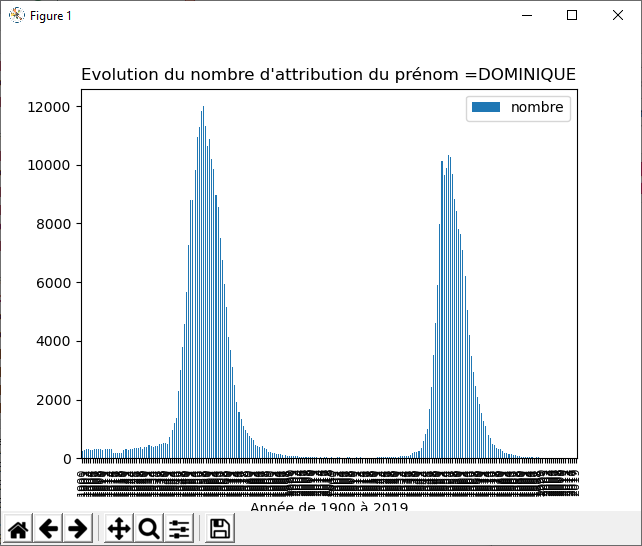
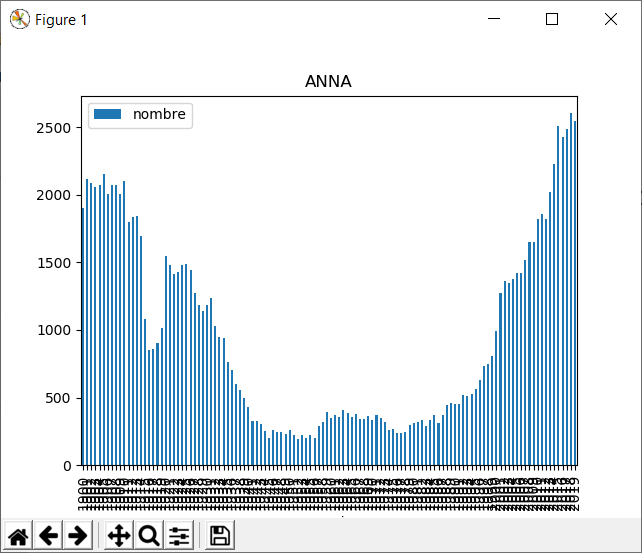
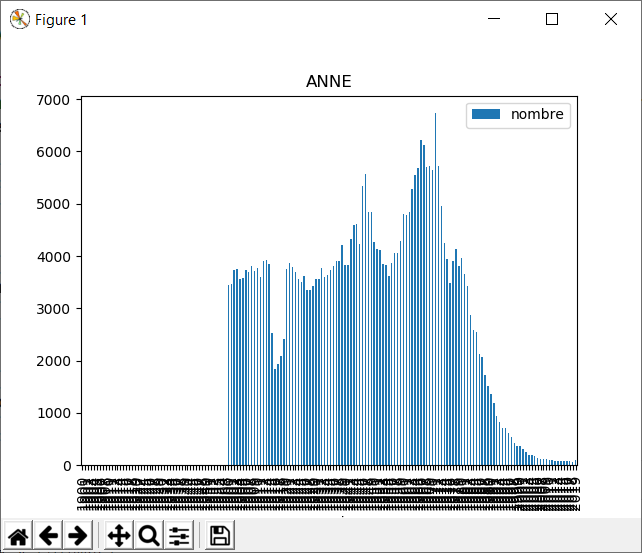
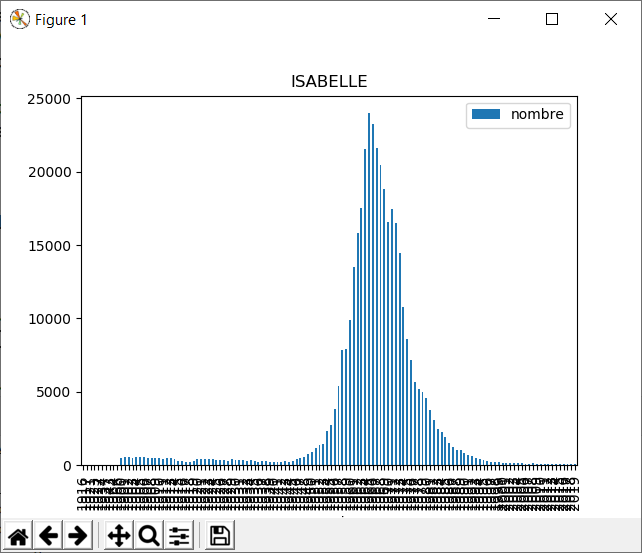
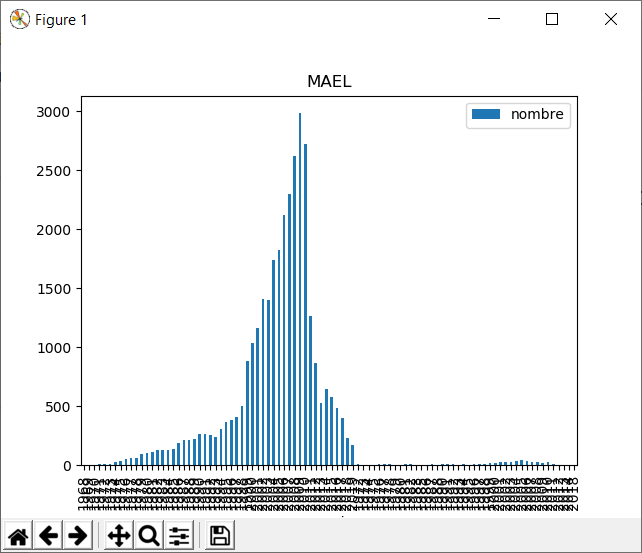
Quelques graphiques de prénoms entre 1900 et 2019. Je vois que le mien sombre dans les limbes... Cela m'étonne quand même, il faudrait vérifier les données ou le script.
En regardant les données, je découvre qu'il existe des femmes qui se prénomment pierre... d'ou peut-être l'erreur. Et en creusant les données je constate Dominique que ton prénom est androgyne, donc je pense que le graphique cumule les hommes puis les femmes ;)
 |
 |
 |
 |
 |
|
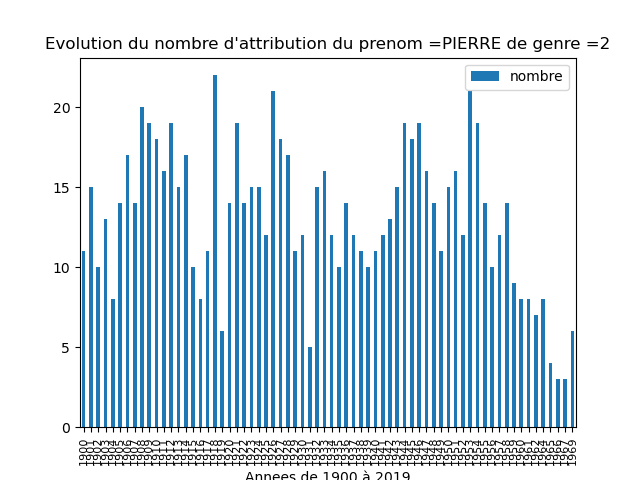
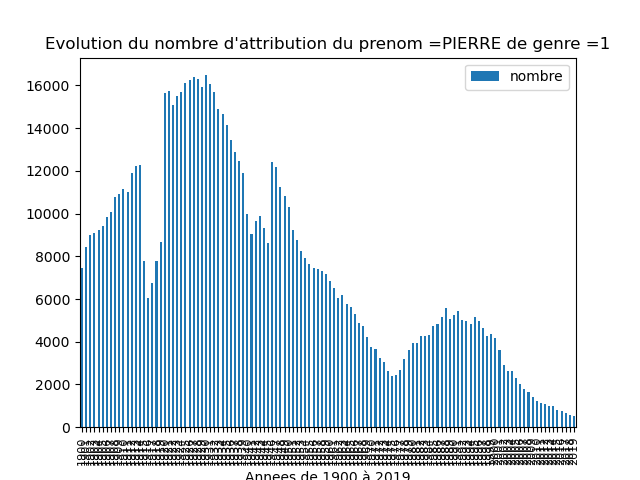
Résolution du mystère des PIERREs et des autres prénoms...
Les bons graphiques sont ceux là car il faut dissocier les PIERRE femmes des PIERRE hommes.
Pour réaliser ces graphiques il faut donc :
- Importer pandas
- Lire les données du fichier nat2019.csv par la méthode de votre choix
- Extraire les données voulues par sexe ET par prénom (attention sexe = 1 ou 2, et c'est une valeur int donc entière!!!)
- Supprimer les XXXX de annais, puis les colonnes sexe et preusuel
- Importer matplotlib
- Faire le graphe du nbre de prénom par année de 1900 à 2019
| PIERRE femme | PIERRE homme |
 |
 |
;-)
| [ ] | 11599 kB | |
| [ ] | 2 kB |
